Sql Server 2014 ile gelen ve Microsoftun üzerine en çok durduğu teknolojilerin başında olan in-Memory OLTP ( Online Transaction Processing ) .
Bu teknolojiyi aslında daha önce 2012 sürümünün SQL Server Parallel Data Warehouse (PDW) yeni adıyla Microsoft Analytics Platform System iş zekası uygulamaları ve büyük veri için geliştirmişti.
Sql server 2012 de bu özelliğin OLTP sistemler için olmadığını duyduğumda açıkcası üzülmüştüm, sonrasında yeni sürüme in-memory teknolojisi geliştirilmesi biz dba ler için gerçekten heyecan verici oldu diyebilirim.
Gelelim işin tekniğine: bilmiş olduğunuz üzere sql server zaten sık kullanılan sorgu sonuçlarını cachede yani bellekte tutuyordu, bunu geliştirip artık manuel olarak bizimde tablo bazlı olarak memorye atabileceğimiz durumlara izin verir hale gelmiş oldu.
Tabi buraya kadar her şey güzel, tablo direk memory den okunacak, diske gidip IO yapmayacak sql server, ama kritik veriyi memory de tutmamız ne derece doğru ?
Kesinlikle doğru değil.
Bu durum için aslında iki seçenek söz konusu, sql server bize memory de tuttuğumuz tablonun ne derece kritik olduğunu düşünüp, bu durumlar için de kendimizi garantiye alabilme imkanı sağlıyor, sağlıyor sağlamasına da bu durumda memory'nin hızından faydalanmamızı engellemiş oluyor. Yani tablomuz her ne kadar memorye alınmış bir tablo olsada sorgunun normal diskten okunan tablo sonuçları ile hemen hemen aynı değerlerde sonuç dönmesine neden oluyor.
Zaten bir çok durumda tanım tablolarımız ve diğer geçici tablolarımızı sorgularımızda kullanmak zorunda kalıyoruz. En azından bu tabloların memory based olması sorgularımız için epeyce bir performans artışına neden olacaktır. Temp table dan farklı olarak statistics oluşacak in-memory tabloda dahada performans sağlamış olacağız.
Özellikle rapor ortamlarını, production ortamdan henüz ayıramamış yapılar için büyük ölçüde rapor sorgularında performans artışları sağlayacaktır. Bu yapıda bir çok mimari geliştirilebilir.
ŞUNU BELİRTMEKTE FAYDA VAR: in-memory oltp özelliği sadece SQL SERVER 2014 Enterprise 64 Bit sürümü tarafından desteklenmektedir.
Bir tablo memorye nasıl alınacak sorusunun cevabı;
1- Önce database üzerinde memory optimized data file group oluşturmamız gerekiyor:
NOT:
Hem tabloyu schema_only mode da create edip, aynı zamanda tabloyu kullanacak sp yi de compiled sp yaparsak bu şekilde in-memory teknolojisinin kaynaklarını dibine kadar kullanmış olur, en yüksek verimi elde etmiş oluruz.
Önemli NOT:
In-Memory teknolojisinin bir yan etkisi daha var, bu da sql servislerinin start up olma zamanları.
Şöyleki memory de tuttuğunuz tablo ve ya tablolarda ki data miktarı arttıkça sql servislerini başlatmanız daha da uzayacaktır.
Detaylı test sonuçların benim yaptığım testlerle çok paralel olmasada kaynak olarak bu adrese bi göz atabilirsiniz.
Bu teknolojiyi aslında daha önce 2012 sürümünün SQL Server Parallel Data Warehouse (PDW) yeni adıyla Microsoft Analytics Platform System iş zekası uygulamaları ve büyük veri için geliştirmişti.
Sql server 2012 de bu özelliğin OLTP sistemler için olmadığını duyduğumda açıkcası üzülmüştüm, sonrasında yeni sürüme in-memory teknolojisi geliştirilmesi biz dba ler için gerçekten heyecan verici oldu diyebilirim.
Gelelim işin tekniğine: bilmiş olduğunuz üzere sql server zaten sık kullanılan sorgu sonuçlarını cachede yani bellekte tutuyordu, bunu geliştirip artık manuel olarak bizimde tablo bazlı olarak memorye atabileceğimiz durumlara izin verir hale gelmiş oldu.
Tabi buraya kadar her şey güzel, tablo direk memory den okunacak, diske gidip IO yapmayacak sql server, ama kritik veriyi memory de tutmamız ne derece doğru ?
Kesinlikle doğru değil.
Bu durum için aslında iki seçenek söz konusu, sql server bize memory de tuttuğumuz tablonun ne derece kritik olduğunu düşünüp, bu durumlar için de kendimizi garantiye alabilme imkanı sağlıyor, sağlıyor sağlamasına da bu durumda memory'nin hızından faydalanmamızı engellemiş oluyor. Yani tablomuz her ne kadar memorye alınmış bir tablo olsada sorgunun normal diskten okunan tablo sonuçları ile hemen hemen aynı değerlerde sonuç dönmesine neden oluyor.
Zaten bir çok durumda tanım tablolarımız ve diğer geçici tablolarımızı sorgularımızda kullanmak zorunda kalıyoruz. En azından bu tabloların memory based olması sorgularımız için epeyce bir performans artışına neden olacaktır. Temp table dan farklı olarak statistics oluşacak in-memory tabloda dahada performans sağlamış olacağız.
Özellikle rapor ortamlarını, production ortamdan henüz ayıramamış yapılar için büyük ölçüde rapor sorgularında performans artışları sağlayacaktır. Bu yapıda bir çok mimari geliştirilebilir.
ŞUNU BELİRTMEKTE FAYDA VAR: in-memory oltp özelliği sadece SQL SERVER 2014 Enterprise 64 Bit sürümü tarafından desteklenmektedir.
Bir tablo memorye nasıl alınacak sorusunun cevabı;
1- Önce database üzerinde memory optimized data file group oluşturmamız gerekiyor:
ALTER DATABASE denemedb ADD FILEGROUP
I_M_oltp_mod CONTAINS
MEMORY_OPTIMIZED_DATA
ALTER DATABASE denemedb ADD FILE (name='I_M_oltp_file', filename='c:\data\I_M_oltp_file')
TO FILEGROUP
I_M_oltp_mod
ALTER DATABASE denemedb SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT=ON
2- Memory-Optimize tablo ve index oluşturulur.
Bu tip memory optimized tablolarda
(data will be persisted) data kritiktir ve güvenlik sağlanır, performansdan kayıp
vardır.
CREATE TABLE dbo.Information ( InfoId INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED,
UserId INT NOT NULL INDEX ix_UserId NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000),
LogDate DATETIME2 NOT NULL
) WITH (MEMORY_OPTIMIZED=ON)
GO
Bu tip memory optimize tablolarda (Data will not be persisted) veri güvenliği
yoktur dolayısıyla, sunucu beklenmedik bir şekilde kapanırsa veri kaybı yaşanır.
diğerinden farkı DURABILITY=SCHEMA_ONLY
olmasıdır.Create sırasında durability belirtilmezse default olarak SCHEMA ve DATA
CREATE TABLE dbo.Users (
Id INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=400000),
CreatedDate DATETIME2 NOT NULL,
ShoppingCartId INT,
INDEX ix_Id NONCLUSTERED
HASH (Id) WITH (BUCKET_COUNT=400000)
)
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY)
GO
Bunları yaptık artık sorgularımız uçarak gelecek diye düşündüğünüzde yanılacaksınız, çünkü in-memory teknolojisinin henüz tüm gücünü kullanamadınız.
Daha yüksek performans için Compiled Stored Procedure(makina dilinde derlenmiş sp) oluşturmamız gerekiyor.
Stored Procedureleri compiled sp yapabilmek için direk sp compiled modda oluşturabileceğimiz gibi mevcut sp mizi compiled moda çevirebiliriz.
Ama bu işlemleri yapmamız için in-memory kısıtlarını (cursor kullanmamak ve data typelar v.b gibi) gözönünde bulundurmamız gerekecek.
Not: Bu tip bir procedure de kullanabileceğiniz tüm objeleri http://msdn.microsoft.com/en-us/library/dn452279.aspx adresinden detaylı olarak kontrol edebilirsiniz.
Varolan stored procedurelerimizin compiled moda convert edip edemeyeceğimiz konusunda microsoft kolaylık oluşturmuş ve wizard ile iki adımda sp deki uygun olmayan obje kullanımlarımızı listeleyecektir.
1. Adım: (sp sağ click => Native Compilation Advisor)
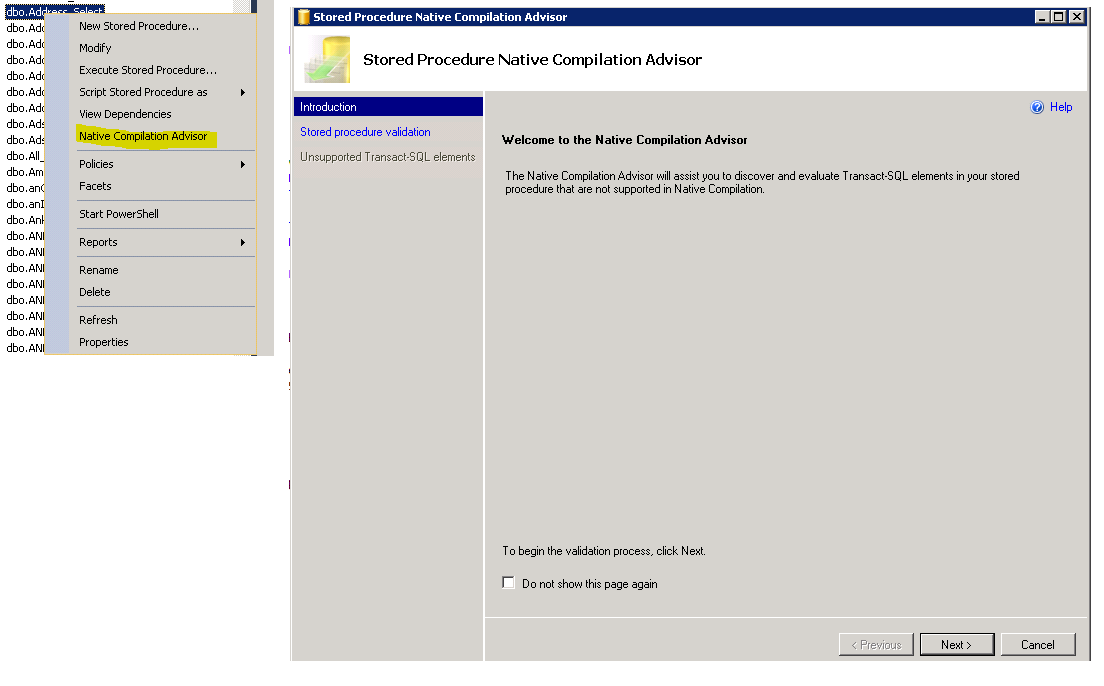

Ama bu işlemleri yapmamız için in-memory kısıtlarını (cursor kullanmamak ve data typelar v.b gibi) gözönünde bulundurmamız gerekecek.
Not: Bu tip bir procedure de kullanabileceğiniz tüm objeleri http://msdn.microsoft.com/en-us/library/dn452279.aspx adresinden detaylı olarak kontrol edebilirsiniz.
Varolan stored procedurelerimizin compiled moda convert edip edemeyeceğimiz konusunda microsoft kolaylık oluşturmuş ve wizard ile iki adımda sp deki uygun olmayan obje kullanımlarımızı listeleyecektir.
1. Adım: (sp sağ click => Native Compilation Advisor)
2. Adım: (Stored procedure validation tab ve Next )
NOT:
Hem tabloyu schema_only mode da create edip, aynı zamanda tabloyu kullanacak sp yi de compiled sp yaparsak bu şekilde in-memory teknolojisinin kaynaklarını dibine kadar kullanmış olur, en yüksek verimi elde etmiş oluruz.
Önemli NOT:
In-Memory teknolojisinin bir yan etkisi daha var, bu da sql servislerinin start up olma zamanları.
Şöyleki memory de tuttuğunuz tablo ve ya tablolarda ki data miktarı arttıkça sql servislerini başlatmanız daha da uzayacaktır.
Detaylı test sonuçların benim yaptığım testlerle çok paralel olmasada kaynak olarak bu adrese bi göz atabilirsiniz.